下面直接来一步一步如何进行启动HDFS并运行MapReduce程序的。
- 1. 修改hadoop-env.sh文件
- 2. 配置core-site.xml
- 3. 配置hdfs-site.xml
- 4. 格式化namenode
- 5. 启动namenode
- 6. 启动datanode
- 7. 查看集群
- 8. 查看日志
- 9. Web端查看HDFS文件系统
- 10. 思考:为什么不能一直格式化NameNode,格式化NameNode需要注意什么?
- 11. 操作集群
1. 修改hadoop-env.sh文件
查看jdk安装路径:
[root@hadoop100 logs]# echo $JAVA_HOME
/opt/module/jdk1.8.0_161
将jdk安装路径复制。修改hadoop-env.sh中的JAVA_HOME部分的内容。如果已经在环境变量里面配置过JAVA_HOME了,这一步可以省略。
[root@hadoop100 ~]# cd /opt/module/
[root@hadoop100 module]# cd hadoop-2.10.0/
[root@hadoop100 hadoop-2.10.0]# vim etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_161
2. 配置core-site.xml
[root@hadoop100 hadoop-2.10.0]# vim etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.10.0/data/tmp</value>
</property>
</configuration>
3. 配置hdfs-site.xml
[root@hadoop100 hadoop-2.10.0]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<!--指定HDFS副本的数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. 格式化namenode
第一次启动时格式化,以后就不要总格式化。
[root@hadoop100 hadoop-2.10.0]# bin/hdfs namenode -format
5. 启动namenode
[root@hadoop100 hadoop-2.10.0]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-zohar-namenode-hadoop100.out
6. 启动datanode
[root@hadoop100 hadoop-2.10.0]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-zohar-datanode-hadoop100.out
7. 查看集群
[root@hadoop100 hadoop-2.10.0]# jps
3121 DataNode
3977 Jps
3052 NameNode
jps是JDK的命令,如果不安装JDK是不能使用jps命名的,并不是Linux命名。
8. 查看日志
[root@hadoop100 hadoop-2.10.0]# cd logs/
[root@hadoop100 logs]# ll
总用量 252
-rw-r--r--. 1 root root 107066 12月 9 12:49 hadoop-root-datanode-hadoop100.log
-rw-r--r--. 1 root root 715 12月 9 12:49 hadoop-root-datanode-hadoop100.out
-rw-r--r--. 1 root root 715 12月 9 12:34 hadoop-root-datanode-hadoop100.out.1
-rw-r--r--. 1 root root 715 12月 9 12:29 hadoop-root-datanode-hadoop100.out.2
-rw-r--r--. 1 root root 715 12月 9 09:06 hadoop-root-datanode-hadoop100.out.3
-rw-r--r--. 1 root root 109258 12月 9 12:49 hadoop-root-namenode-hadoop100.log
-rw-r--r--. 1 root root 715 12月 9 12:48 hadoop-root-namenode-hadoop100.out
-rw-r--r--. 1 root root 715 12月 9 12:34 hadoop-root-namenode-hadoop100.out.1
-rw-r--r--. 1 root root 715 12月 9 12:29 hadoop-root-namenode-hadoop100.out.2
-rw-r--r--. 1 root root 715 12月 9 09:06 hadoop-root-namenode-hadoop100.out.3
-rw-r--r--. 1 root root 763 12月 9 14:16 hadoop-root-nanenode-hadoop100.out
-rw-r--r--. 1 root root 0 12月 9 09:06 SecurityAuth-root.audit
[root@hadoop100 logs]# cat hadoop-root-datanode-hadoop100.log
9. Web端查看HDFS文件系统
打开虚拟机中的浏览器并输入输入:http://192.168.1.100:50070
即可查看HDFS的内容。
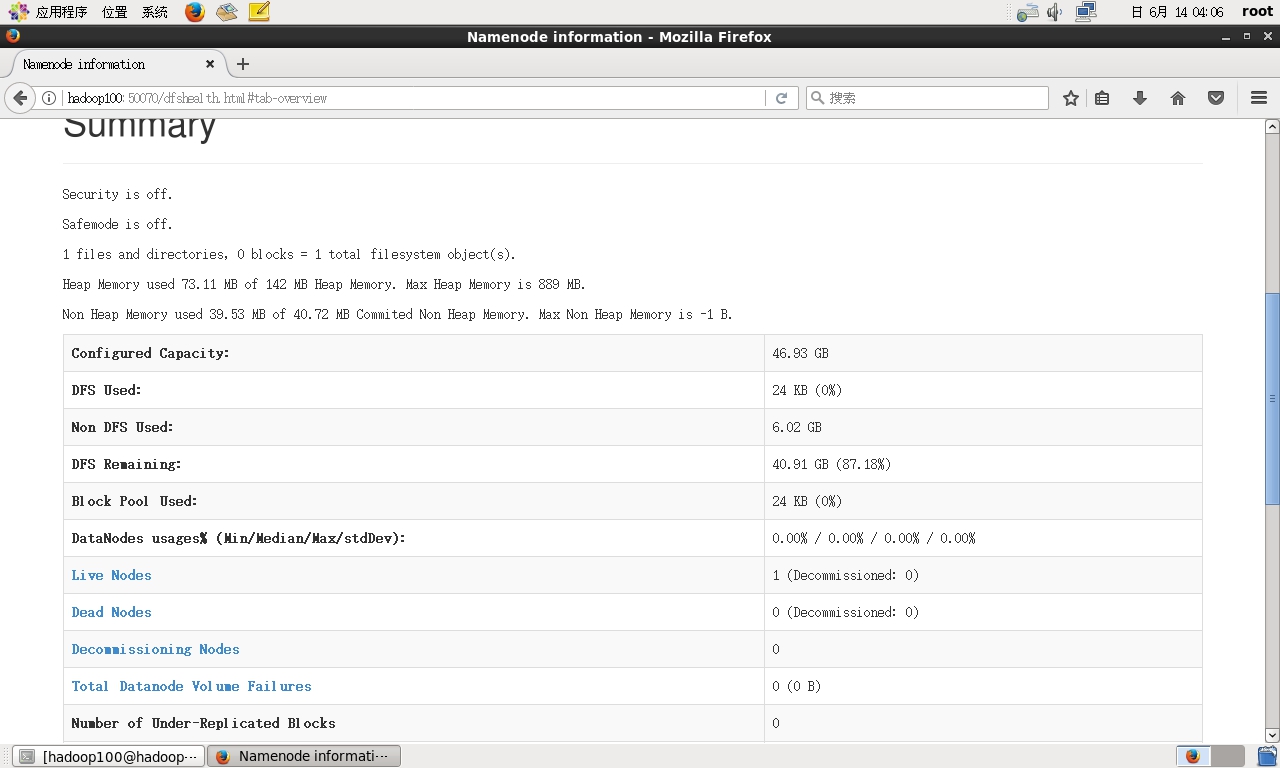
注意:如果不能查看,请把防火墙关闭了。 关闭防火墙操作:
service iptables stop chkconfig iptables off
小提示:如果关闭虚拟机的防火墙,用windows的浏览器也是可以进行访问的。
10. 思考:为什么不能一直格式化NameNode,格式化NameNode需要注意什么?
查看/opt/module/hadoop-2.7.2/data/tmp/dfs目录(这个目录也就是在编辑core-site.xml指定的运行时产生的数据的存储目录)下生成的name和data目录,如下所示;
[zohar@hadoop100 hadoop-2.7.2]$ cd data/tmp/dfs/
[zohar@hadoop100 dfs]$ cat name/current/VERSION
#Sun Jun 14 03:58:23 CST 2020
namespaceID=1142092124
clusterID=CID-65d0ae3d-dff4-4005-966f-df4d052e9f9a
cTime=0
storageType=NAME_NODE
blockpoolID=BP-312741995-192.168.1.100-1592078303005
layoutVersion=-63
[zohar@hadoop100 dfs]$ cat data/current/VERSION
#Sun Jun 14 04:00:20 CST 2020
storageID=DS-a90239a2-a29d-4395-bdba-a889d7206ef0
clusterID=CID-65d0ae3d-dff4-4005-966f-df4d052e9f9a
cTime=0
datanodeUuid=6bc18248-ec2a-471b-a392-d4adb189c4da
storageType=DATA_NODE
layoutVersion=-56
有没有发现他们的集群号clusterID都是一样的。
因此,格式化NameNode会产生新的集群ID,这样会导致NameNode和DataNode的集群ID不一致,集群找不到已往的数据,所以,格式NameNode时,一定要先删除data数据和log日志,然后在格式化NameNode。
11. 操作集群
11.1. 在HDFS上创建一个input文件夹
[root@hadoop100 hadoop-2.10.0]# bin/hdfs dfs -mkdir -p /user/zohar/input
11.2. 把测试文件上传到文件系统上
这里先切换到hadoop的根目录下,然后进行下面的操作。
[root@hadoop100 hadoop-2.10.0]# bin/hdfs dfs -put wcinput/wc.input /user/zohar/input/
这里把前面单机测试的wc.input文件上传到HDFS文件系统中的对应的目录下。wc.input文件也就是一些用户自己编写的字符串内容。
11.3. 查看上传的文件
[root@hadoop100 hadoop-2.10.0]# bin/hdfs dfs -ls /user/zohar/input
-rw-r--r-- 1 root supergroup 59 2019-12-10 07:56 /user/zohar/input/wc.input
[root@hadoop100 hadoop-2.10.0]# bin/hdfs dfs -cat /user/zohar/input/wc.input
zhangzhihong hadoop helloworld zhangzhihong a this a haha
11.4. 运行mapreduce程序
[root@hadoop100 hadoop-2.10.0]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /user/zohar/input/ /user/zohar/output
这里输入的命令和单机模式的意思也是一样的,运行wordcount的程序,只不过输入输出的文件都是对应在HDFS文件系统上,而不是本机上面的文件。这里
/user/zohar/input和/user/zohar/output都是指定在HDFS文件系统之上的。
11.5. 查看输出的结果
[root@hadoop100 hadoop-2.10.0]# bin/hdfs dfs -cat /user/zohar/output/*
a 2
hadoop 1
haha 1
helloworld 1
this 1
zhangzhihong 2
当然也可以通过虚拟机中的浏览器查看到:http://hadoop100:50070/

11.6. 将测试文件下载到本地
[root@hadoop100 hadoop-2.10.0]# hadoop fs -get /user/zohar/output/part-r-00000 ./wcoutput/
查看下载内容
[root@hadoop100 hadoop-2.10.0]# cd wcoutput/
[root@hadoop100 wcoutput]# ls -l
总用量 4
-rw-r--r--. 1 root root 55 12月 8 08:57 part-r-00000
-rw-r--r--. 1 root root 0 12月 8 08:57 _SUCCESS
11.7. 删除输出结果
[root@hadoop100 hadoop-2.10.0]# hdfs dfs -rm -r /user/zohar/output
Deleted /user/zohar/output
刷新一下浏览器,就可以看到上图的显示的结果就不存在了。