1. 数据收集
1.1. Sqoop
Sqoop是为了就解决关系数据库与Hadoop之间数据传输问题,构建了这两者之间的“桥梁”。
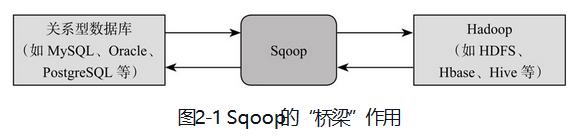
Sqoop采用Connecter架构,主要负责从特定数据源中抽取和加载数据。
Sqoop主要具备以下特点:
- 性能高:Sqoop采用MapReduce完成数据的导入和导出,具有MapReduce的并发度可控、容错性高、扩展性高等优点;
- 自动类型转换:Sqoop可读取数据元信息,自动完成数据类型映射,也可自定义类型映射关系;
- 自动传播元信息:Sqoop在发送端和接收端传递数据的同时,也会将元信息传递过去,保证接收端和发送端有一致的元信息。
1.2. Flume
如何高效收集各种各样的日志,并发送到后端存储系统(比如Hadoop、数据仓库等)中进行统一分析和挖掘,是每个公司需要解决的问题。
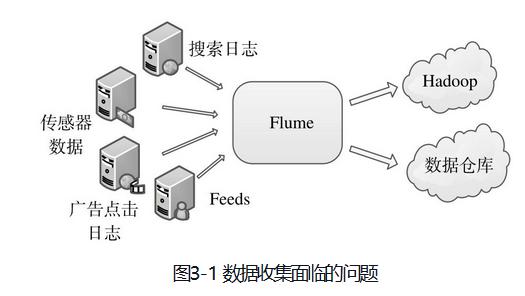
日志收集面临的问题:
- 数据源种类多:各种服务均会产生日志,格式也不通过,产生的日志方式也不同;
- 数据源是物理分布的:各种服务运行在不同的机器上,有的甚至跨机房的;
- 流式的不间断产生:日志实时产生,需要实时收集便于后端的分析和挖掘。
Flume系统是解决以上流式数据收集问题的,是一个通过用的六十数据收集系统,可以将不同的数据源产生的流式数据接近实时的发送到后端中心化的存储系统中,具有分布式、良好的可靠性和可用性等优点。
Flume系统的特点:
- 良好的扩展性:Flume架构是完全分布式的,容易扩展;
- 高度定制化:各个组件是可插拔的,可根据需求进行定制;
- 声明式动态化配置:可根据需求动态配置基于Flume的数据流拓扑结构。
- 内置支持事务。
Flume的数据流是通过一系列Agent组件构成的。
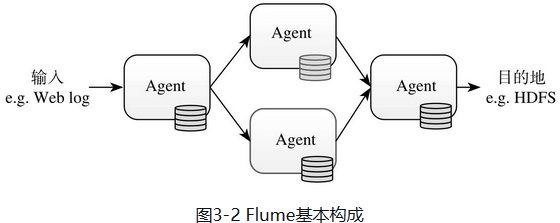
Agent内部三个组件:Souce、Channel、Sink。

1.3. Kafka分布式消息队列
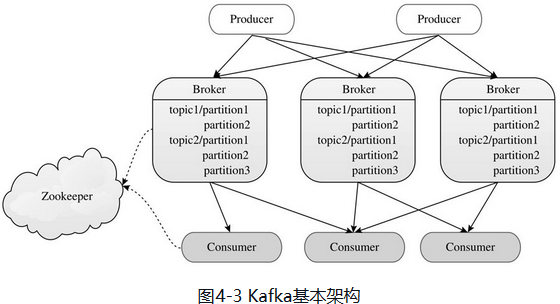
Kafka架构有Producer、Broker和Consumer组件构成,其中Producer将数据写入Broker,Consumer从Broker上读取数据进行处理,Broker构成了链接Producer和Comsumer的“缓冲区”。Broder中的消息被划分为若干个Topic,同属一个Topic的所有数据按照某种策略分为多个分区,从而实现负载分摊和数据并行处理。Borker和Comsumer通过Zookeeper协调和服务发现。
Kafka采用了顺序读写和批量写机制。Kafka将数据分区保存,并将每个分区保存成多份以提高数据可靠性。
1.3.1. Kafka各个组件
- Producer
将数据转化成“消息”,并通过网络发送给Broker。
- Broker
接受Producer和Consumer的请求,把消息持久化到本地磁盘。
- Consumer
主动从Kafka Broder拉取消息进行处理。
- ZooKeeper
ZooKeeper担任分布式服务协调的作用,Broker和Consumer直接依赖于zookeeper才能正常工作。
2. 数据存储
问题:
- 数据序列化:将内存对象转化为字节流的过程,直接决定了数据解析效率以及模式演化能力。
- 文件存储格式:文件存储格式是数据在磁盘上的组织方式,直接决定了数据存取效率以及被上层分布式计算机集成的容易程度。
- 存储系统:分布式文件系统HDFS和分布式数据库系统HBase。
2.1. 数据序列化
2.1.1. 解决方案
Facebook Thrift, Google Protocol Buffers, Apache Avro。
2.1.2. 常见的存储格式
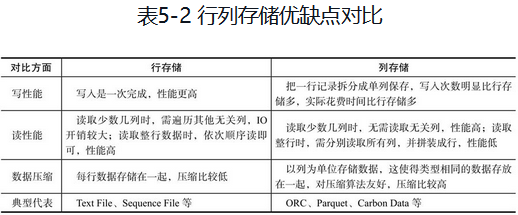
存储格式分为:行式存储和列式存储。
- 行式存储:文本格式、key/value二进制格式Squence File。
- 列式:ORC, Parquet, Carbon Data。
2.1.3. 行列存储格式的优缺点
2.2. 分布式文件系统-HDFS
数据存储扩容方案:纵向扩展(scale-up)和横向扩展(scale-out)。
- 纵向扩展:利用现有的存储系统,通过不断增加存储容量来满足数据增长的需求;
- 横向扩展:以网络互连的节点为单位扩大存储容量(集群)。
HDFS采用的是一种快级别的分布式文件系统。
2.2.1. HDFS基本架构
采用主从架构,主节点:NameNode,只有一个;从节点:DataNode,通常有多个,存储实际的数据块。
- NameNode
HDFS集群的管理者,负责管理文件系统元信息和所有的DataNode。
- DataNode
存储实际的数据块,并周期性通过心跳想NameNode汇报自己的状态信息。
- Client
用户通过客户端与NameNode和DataNode交互,完成HDFS管理和数据读写操作。文件的分块操作也是在客户端上完成的。
2.2.2. HDFS副本放置策略
默认采用的是三副本放置策略。
- 客户端和DataNode在一个节点上(上图a):第一个副本写到同节点的DataNode上,另外两个副本卸载两一个相同机架的不同DataNode上;
- 客户端和DataNode不同节点(上图b):HDFS随机选择一个DataNode作为第一个副本放置节点,其他两个副本写到两一个相同机架的不同DataNode上。
2.3. HBase
2.3.1. 逻辑数据模型
HBase分为namsespace和table,一个namespace中包含一组table,默认有两个namespace。
- rowkey: 标识,类似于关系数据库中的“主键”,每行数据有一个rowkey,唯一标识该行,全局有序,没有数据类型,以字节数组形式保存。
- column family:每行数据拥有相同的column family,是访问控制的基本单位,同一个column family中的数据在物理上会存储在一个文件中。
- column qualifier:column family内部列标识,无数据类型,以字节数组形式存储。
- cell:通过rowkey、column family和 column qualifier可唯一定位一个cell。
- timestamp:时间戳。
2.3.2. 物理数据存储
HBase是列簇存储引擎,同一列簇中的数据会单独存储,但列簇内数据是行式存储的。
3. 分布式协调与资源管理
3.1. 分布式协调服务ZooKeeper
3.1.1. zookeeper数据模型
- 层级命名空间
每个节点成为“znode”。
- data:每个znode有一个数据域,记录用户数据,类型为字节数组。
- type:znode类型,具体分为persistent, ephemeral, persistent_sequential和ephemeral_sequential.
- persistent:持久化节点,能够一直可靠的保持该节点(除非用户显示删除)。
- ephemeral:临时节点,只要客户端保持与zookeeper server的session不断开,该节点会一直存在,一旦两者之间连接断开,那么该节点也将自动删除。
- sequential:自动在文件名默认追加一个增量的唯一数字来记录文件创建顺序,通常与上面两者连用。
- version:版本号,数据每变动一次加1。
- children:znode可以包含子节点,但是ephemeral类型的znode与session生命周期绑定的,zookeeper不允许ephemeral znode有子节点。
- ACL:znode访问控制列表,用户可以单独设置每个znode可访问的用户列表。
- Watcher
Watcher是zookeeper提供的订阅/发布机制,用户在某个znode上注册watcher来监听发生的变化。watcher一旦触发后便会被删除,除非用户再次注册该watcher。
- Session
Session是客户端与zookeeper服务端之间通信通道。同一个session中的消息是有序的。session具有容错性:如果客户端连接的zookeeper服务器宕机,客户端会自动连接到其他活着的服务器上。
zookeeper基本架构
zookeeper通常有奇数个zookeeper实例构成,其中一个实例为leader,其他为follow,同时维护层及目录结构的一个副本,通过ZAB(zookeeper atomic broadcast)协议维持副本之间的一致性。
- 读:每一个zookeeper实例均可以提供读服务,实例越多,读吞吐率越高。
- 写:每一个zookeeper实例都可以接受客户端的写服务,但是需要进一步转发给leader协调完成分布式写。
ZAB协议规定,只要多数zookeeper实例写成功,就可以认为写是成功的。因此2N+1和2N+2个节点都是具备相同的容错能力,所以部署奇数个节点。
资源管理和调度系统YARN
- 提高集群资源利用率;
- 服务自动化部署。
YARN基本结构
YARN主要由ResourceManager、NodeManager、ApplicationMaster(图中给出了MapReduce和MPI两种计算框架ApplicationMaster,分别为MR AppMstr和MPI AppMstr)和Container等几个组件构成。
-
ResourceManager(RM)
-
ApplicationMaster(AM)
-
NodeManager(NM)
-
Container
大数据计算引擎
批处理引擎MapReduce
MapReduce主要由两部分组成:编程模型和运行时环境。编程模型为用户提供了非常易用的编程接口,二其他复杂的工作,全部由MapReduce运行时环境完成。
两个阶段:
- Map阶段:由多个可并行执行的Map构成,主要功能是,将待处理数据集按照数据量大小切分为等大的数据分片,每个分片交由一个任务处理。
- Reduce阶段:由多个可并行执行的ReduceTask构成,对前一阶段中各个任务产生的结果进行规约,得到最终结果。