MySQL必知必会 阅读笔记
zohar.zzh
2019-2-12
第1章 了解SQL
这一章节讲解了基本的概念,比如:数据库、表、列(column)、数据类型、行(row)、主键。基本了解即可。
- 数据库:保存有组织的数据的容器。
- 表:某种特定类型数据的结构化清单。
- 模式(scheme):关于数据库和表的布局以及特性的信息。
- 列:表中的一个字段。所有表都是由一列或者多列组成。
- 数据类型:数据的类型。
- 行:表中的一个记录。
- 主键:一列(或者一组列)其值能够唯一区别表中的每个行。
第2章 MySQL简介
介绍了MySQL和MySQL工具(命令行、MySQL Administrator、MySQL Query Browser)。后面两个工具都是图形化界面,前者是管理,后者是能够编写和执行SQL命令。
第21章 创建和操作数据库和表
这本书的把创建表写在后面了,所以就把创建数据库和表写在前面来。
21.0 创建数据库
- 创建数据库
create database crashcourse;
- 切换到该数据库
use crashcourse;
21.1 创建表
使用crate table 表名();
- 创建customer表
create table customers( cust_id int not null auto_increment, cust_name char(50) not null, cust_address char(50) null, cust_city char(50) null, cust_state char(5) null, cust_zip char(10) null, cust_country char(50) null, cust_contact char(50) null, cust_email char(255) null, primary key (cust_id) )engine=InnoDB;需要理解的部分:
- auto_inrement:就是自增长,每个表只能允许1列使用auto_increment,而且必须被索引(如:通过成为主键);
- primary key(cust_id):让该列成为主键;
- engine=InnoDB:设置引擎类型,可选的引擎类型:InnoDB(可靠事务处理引擎,但是不支持全文本搜索)、MEMORY(功能等同与MyISAM,数据存储于内存,速度快,适用于临时表)、MyISAM(支持全文本搜索,但不支持事务处理)。
- 创建order表
create table orders( order_num int not null auto_increment, order_date datetime not null, cust_id int not null, primary key (order_num) )engine = InnoDB;需要注意的部分:
- datetime数据类型:是date和time的组合。
- 创建vendor表
create table vendors( vend_id int not null auto_increment, vend_name char(50) not null, vend_address char(50) null, vend_city char(50) null, vend_state char(5) null, vend_zip char(10) null, vend_country char(50) null, primary key (vend_id) )engine=InnoDB; - 创建orderitems表
create table orderitems( order_num int not null, order_item int not null, prod_id char(10) not null, quantity int not null, item_price decimal(8,2) not null, primary key (order_num,order_item) )engine=InnoDB;注意部分:
- 多个列组成一个主键的格式,用逗号隔开;
- 设置默认值,比如这个表格中的quantity列设置:
quantity int not null default 1这个就是设置默认值为1。
- 创建product表
create table produces( prod_id char(10) not null, vend_id int not null, prod_name char(255) not null, prod_price decimal(8,2) not null, prod_desc text null, primary key (prod_id) )engine=InnoDB;注意部分:
- text数据类型:最大长度为64K的变长文本。
- 创建productnotes表
create table productnotes( note_id int not null auto_increment, prod_id char(10) not null, note_date datetime not null, note_text text null, primary key(note_id), fulltext(note_text) )engine = MyISAM;需要注意的部分
- fulltext(note_text):全文本搜索。
- 引擎类型设置为:MyISAM.
21.2 更新表
使用alter table语句。
- 给表添加一列:
alter table vendors add vend_phone char(20);需要注意的部分:
- 更新表用alter table;
- 给一个表增加一列的格式为: add 列名 数据类型;
- 给表删除一列:
alter table vendors drop column vend_phone;需要注意的部分:
- 删除表中的一列格式为:drop column 列名;
- 设置表的外键(alter table的常见用途) ``` alter table orderitems add constraint fk_orderitems_orders foreign key(order_num) references orders(order_num);
alter table orderitems add constraint fk_orderitems_products foreign key(prod_id) references products(prod_id);
alter table orders add constraint fk_orders_customers foreign key(cust_id) references customers(cust_id);
alter table products add constraint fk_products_vendors foreign key(vend_id) references vendors(vend_id);
> 需要注意的部分:
> 1. 设置外键格式:alter table <表名> add constraint <限制名称> foreign key(外键列) references <外表(外键列)>;
* 重命名表
rename table <表名称> to <新表名称>;
* 重命名多个表
rename table <表名称1> to <新表名称1>,<表名称2> to <新表名称2>;
* 删除表
drop table <表名称>;
# 第3章 使用MySQL
* 显示数据库
输入:show databases;
输出: +——————–+ | Database | +——————–+ | information_schema | | crashcourse | | mysql | | performance_schema | | sys | +——————–+ 5 rows in set (0.00 sec)
* 显示表
输入:show tables;
输出: +———————–+ | Tables_in_crashcourse | +———————–+ | customers | | orderitems | | orders | | productnotes | | products | | vendors | +———————–+ 6 rows in set (0.00 sec)
* 显示表列:
输入:show columns from <表名称>;
输出: +————–+———–+——+—–+———+—————-+ | Field | Type | Null | Key | Default | Extra | +————–+———–+——+—–+———+—————-+ | cust_id | int(11) | NO | PRI | NULL | auto_increment | | cust_name | char(50) | NO | | NULL | | | cust_address | char(50) | YES | | NULL | | | cust_city | char(50) | YES | | NULL | | | cust_state | char(5) | YES | | NULL | | | cust_zip | char(10) | YES | | NULL | | | cust_country | char(50) | YES | | NULL | | | cust_contact | char(50) | YES | | NULL | | | cust_email | char(255) | YES | | NULL | | +————–+———–+——+—–+———+—————-+ 9 rows in set (0.00 sec)
# 第19章 插入数据
* 插入完整的行
insert into <表名称> values(null,'zohar.zzh','90046',null,null);
> 需要注意的部分:
> 1. 插入数据用insert into;
> 2. 这个格式只列出表名称,所以给出的values(x,x,x)需要与表给出的顺序一致;
> 3. 加入第一列为主键且设置为auto_increment,那么第一列的数据值可以设置为null。当你不想给出或者设置这个值的时候,就可以按照直接写成null这种方法来处理。
insert into <customers(cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email)> values(x,x,x,x,x,…);
> 需要注意的部分:
> 1. 列出了部分列数。
* 出入多行数据
insert into <表名称(x,x,x)> values (x,x,x),(x,x,x),(x,x,x);
> 注意点:
> 1. 插入多行数据就是在values后面用逗号,进行分隔。
# 第4章 检索数据
* 查询单列
输入:select prod_name from products;
输出: +—————-+ | prod_name | +—————-+ | .5 ton anvil | | 1 ton anvil | | 2 ton anvil | | Detonator | | Bird seed | | Carrots | | Fuses | | JetPack 1000 | | JetPack 2000 | | Oil can | | Safe | | Sling | | TNT (1 stick) | | TNT (5 sticks) | +—————-+
* 查询多列
输入:select prod_id,prod_name,prod_price from products;
输出: +———+—————-+————+ | prod_id | prod_name | prod_price | +———+—————-+————+ | ANV01 | .5 ton anvil | 5.99 | | ANV02 | 1 ton anvil | 9.99 | | ANV03 | 2 ton anvil | 14.99 | | DTNTR | Detonator | 13.00 | | FB | Bird seed | 10.00 | | FC | Carrots | 2.50 | | FU1 | Fuses | 3.42 | | JP1000 | JetPack 1000 | 35.00 | | JP2000 | JetPack 2000 | 55.00 | | OL1 | Oil can | 8.99 | | SAFE | Safe | 50.00 | | SLING | Sling | 4.49 | | TNT1 | TNT (1 stick) | 2.50 | | TNT2 | TNT (5 sticks) | 10.00 | +———+—————-+————+
* 查询所有数据
select * from products;
* 查询出不同的行(不显示重复的行)
mysql> select vend_id from products; +———+ | vend_id | +———+ | 1001 | | 1001 | | 1001 | | 1002 | | 1002 | | 1003 | | 1003 | | 1003 | | 1003 | | 1003 | | 1003 | | 1003 | | 1005 | | 1005 | +———+
> 这里可以看到有重复的值,如何消除重复呢?使用distinct
mysql> select distinct vend_id from products; +———+ | vend_id | +———+ | 1001 | | 1002 | | 1003 | | 1005 | +———+
> 当distinct应用于多个列,只有当多个列中的内容都相同,才会不显示,否则都会显示出来。
> ```
> mysql> select distinct vend_id,prod_price from products;
>+---------+------------+
>| vend_id | prod_price |
>+---------+------------+
>| 1001 | 5.99 |
>| 1001 | 9.99 |
>| 1001 | 14.99 |
>| 1003 | 13.00 |
>| 1003 | 10.00 |
>| 1003 | 2.50 |
>| 1002 | 3.42 |
>| 1005 | 35.00 |
>| 1005 | 55.00 |
>| 1002 | 8.99 |
>| 1003 | 50.00 |
>| 1003 | 4.49 |
>+---------+------------+
> ```
> 这里就是一个列子,如果这里有一列不同,就会显示出来。
* 限制结果
mysql> select prod_name from products limit 5; +————–+ | prod_name | +————–+ | .5 ton anvil | | 1 ton anvil | | 2 ton anvil | | Detonator | | Bird seed | +————–+
> 注意:
> 1. limit 5:从起始的0行到第4行,总共5行。
> 2. 起始行是从0开始的。
mysql> select prod_name from products limit 5,5; +————–+ | prod_name | +————–+ | Carrots | | Fuses | | JetPack 1000 | | JetPack 2000 | | Oil can | +————–+
> 注意:
> 1. limit 5,5:第一个数是起始行,第二个数是偏移数
> 2. 当第2个数大于表中所有行的总数时,有多少行就列出多少行。
> e.g.
> ```
>mysql> select prod_name from products limit 10,5;
>+----------------+
>| prod_name |
>+----------------+
>| Safe |
>| Sling |
>| TNT (1 stick) |
>| TNT (5 sticks) |
>+----------------+
>```
> 只显示了4行。
> 3. 当第一个数都大于表中的所有行时,就直接输出空的结果。
> e.g.
>```
>mysql> select prod_name from products limit 14,5;
>Empty set (0.00 sec)
>```
* 使用完全限定的表名(列前面用表名限定)
mysql> select products.prod_name from products;
* 表名也可以完全限定的名称(表名前用数据库名限定)
mysql> select products.prod_name from crashcourse.products;
# 第5章 排序查询数据(order by)
* 排序数据
mysql> select prod_name from products order by prod_name; +—————-+ | prod_name | +—————-+ | .5 ton anvil | | 1 ton anvil | | 2 ton anvil | | Bird seed | | Carrots | | Detonator | | Fuses | | JetPack 1000 | | JetPack 2000 | | Oil can | | Safe | | Sling | | TNT (1 stick) | | TNT (5 sticks) | +—————-+
> 默认按照升序进行排列(ASC)。
* 按照多个列排序
mysql> select prod_id,prod_price,prod_name from products order by prod_price,prod_name; +———+————+—————-+ | prod_id | prod_price | prod_name | +———+————+—————-+ | FC | 2.50 | Carrots | | TNT1 | 2.50 | TNT (1 stick) | | FU1 | 3.42 | Fuses | | SLING | 4.49 | Sling | | ANV01 | 5.99 | .5 ton anvil | | OL1 | 8.99 | Oil can | | ANV02 | 9.99 | 1 ton anvil | | FB | 10.00 | Bird seed | | TNT2 | 10.00 | TNT (5 sticks) | | DTNTR | 13.00 | Detonator | | ANV03 | 14.99 | 2 ton anvil | | JP1000 | 35.00 | JetPack 1000 | | SAFE | 50.00 | Safe | | JP2000 | 55.00 | JetPack 2000 | +———+————+—————-+
> 1. 按照多个列进行排序也就是用逗号隔开。
> 2. 多个列排序的显示规则:order by后的第一个列是主要的排列顺序,第二个列,是在第一个列中有相同的数据中进行排序,以此类推,第三个列实在第二个列有相同数据中进行排序。
* 指定排序方向
mysql> select prod_id,prod_price,prod_name from products order by prod_price desc; +———+————+—————-+ | prod_id | prod_price | prod_name | +———+————+—————-+ | JP2000 | 55.00 | JetPack 2000 | | SAFE | 50.00 | Safe | | JP1000 | 35.00 | JetPack 1000 | | ANV03 | 14.99 | 2 ton anvil | | DTNTR | 13.00 | Detonator | | FB | 10.00 | Bird seed | | TNT2 | 10.00 | TNT (5 sticks) | | ANV02 | 9.99 | 1 ton anvil | | OL1 | 8.99 | Oil can | | ANV01 | 5.99 | .5 ton anvil | | SLING | 4.49 | Sling | | FU1 | 3.42 | Fuses | | FC | 2.50 | Carrots | | TNT1 | 2.50 | TNT (1 stick) | +———+————+—————-+
> 1. desc:为降序,asc为升序(默认)。
* 多列指定排序方向
mysql> select prod_id,prod_price,prod_name from products order by prod_price desc,prod_name asc; +———+————+—————-+ | prod_id | prod_price | prod_name | +———+————+—————-+ | JP2000 | 55.00 | JetPack 2000 | | SAFE | 50.00 | Safe | | JP1000 | 35.00 | JetPack 1000 | | ANV03 | 14.99 | 2 ton anvil | | DTNTR | 13.00 | Detonator | | FB | 10.00 | Bird seed | | TNT2 | 10.00 | TNT (5 sticks) | | ANV02 | 9.99 | 1 ton anvil | | OL1 | 8.99 | Oil can | | ANV01 | 5.99 | .5 ton anvil | | SLING | 4.49 | Sling | | FU1 | 3.42 | Fuses | | FC | 2.50 | Carrots | | TNT1 | 2.50 | TNT (1 stick) | +———+————+—————-+
> 1. prod_price指定为降序,prod_name指定为升序。
> 2. 如果是多个列,需要对每个列制定顺序,asc可以省略,因为默认。
* order by与limit组合找到最大最小数据
mysql> select prod_price from products order by prod_price desc limit 1; +————+ | prod_price | +————+ | 55.00 | +————+
> 1. 找到最大的价格数据,prod_price 设置为降序,limit显示输出1个数据,也就是最大的数据。
> 2. 注意order by 和limit的位置,order by 在 from 之后,limit 之前。limit在order by之后。
# 第6章 过滤数据(where)
* 检索出指定的值的数据
1. =的使用
mysql> select prod_name,prod_price from products where prod_name = “fuses”; +———–+————+ | prod_name | prod_price | +———–+————+ | Fuses | 3.42 | +———–+————+
> 1. 检索出prod_name的值为“fuses”的数据。
> 2. where的位置位于from之后,如果有order by语句,那么order by 位于where之后。
> 3. mysql默认不区分大小写。如果要区分,需要DBA去设置。
> 4. 字符串数据用“ ”。
2. <的使用
mysql> select prod_name,prod_price from products where prod_price < 10; +—————+————+ | prod_name | prod_price | +—————+————+ | .5 ton anvil | 5.99 | | 1 ton anvil | 9.99 | | Carrots | 2.50 | | Fuses | 3.42 | | Oil can | 8.99 | | Sling | 4.49 | | TNT (1 stick) | 2.50 | +—————+————+
> 1. 检索出价格小于10元的数据
3. <=的使用
mysql> select prod_name,prod_price from products where prod_price <= 10; +—————-+————+ | prod_name | prod_price | +—————-+————+ | .5 ton anvil | 5.99 | | 1 ton anvil | 9.99 | | Bird seed | 10.00 | | Carrots | 2.50 | | Fuses | 3.42 | | Oil can | 8.99 | | Sling | 4.49 | | TNT (1 stick) | 2.50 | | TNT (5 sticks) | 10.00 | +—————-+————+
> 1. 检索出价格小于等于10的数据
4. <>/!= 的使用
mysql> select vend_id,prod_price from products where vend_id <> 1003; +———+————+ | vend_id | prod_price | +———+————+ | 1001 | 5.99 | | 1001 | 9.99 | | 1001 | 14.99 | | 1002 | 3.42 | | 1005 | 35.00 | | 1005 | 55.00 | | 1002 | 8.99 | +———+————+
> 1. 检索出vend_id不等于1003的数据。
> 2. 将<>修改成!=的效果是一样的。
5. between的使用
mysql> select prod_name,prod_price from products where prod_price between 5 and 10; +—————-+————+ | prod_name | prod_price | +—————-+————+ | .5 ton anvil | 5.99 | | 1 ton anvil | 9.99 | | Bird seed | 10.00 | | Oil can | 8.99 | | TNT (5 sticks) | 10.00 | +—————-+————+
> 1. 检索出价格为5到10之间的数据。
> 2. between需要两个数据,且两个数据用and进行连接。
* 空值检查
mysql> select cust_id from customers where cust_email is null; +———+ | cust_id | +———+ | 10002 | | 10005 | +———+
> 1. 检查customers表中的email是否为null。
> 2. 用is null来判断。
# 第7章 数据过滤(where通过and/or组合,in/not操作符的使用)
* and操作符
mysql> select vend_id,prod_price,prod_name from products where vend_id=1003 and prod_price<=10; +———+————+—————-+ | vend_id | prod_price | prod_name | +———+————+—————-+ | 1003 | 10.00 | Bird seed | | 1003 | 2.50 | Carrots | | 1003 | 4.49 | Sling | | 1003 | 2.50 | TNT (1 stick) | | 1003 | 10.00 | TNT (5 sticks) | +———+————+—————-+
> 1. 查询出vend_id = 1003 并且价格小于等于10的数据。
> 2. 每多添加一个条件就用and进行连接。
* or操作符
mysql> select vend_id,prod_name from products where vend_id = 1002 or vend_id = 1003; +———+—————-+ | vend_id | prod_name | +———+—————-+ | 1003 | Detonator | | 1003 | Bird seed | | 1003 | Carrots | | 1002 | Fuses | | 1002 | Oil can | | 1003 | Safe | | 1003 | Sling | | 1003 | TNT (1 stick) | | 1003 | TNT (5 sticks) | +———+—————-+
> 1. 找出vend_id = 1002 或者 1003的数据。
* and和or操作符的优先级
mysql> select prod_name,prod_price from products where (vend_id = 1002 or vend_id = 1003) and prod_price >= 10; +—————-+————+ | prod_name | prod_price | +—————-+————+ | Detonator | 13.00 | | Bird seed | 10.00 | | Safe | 50.00 | | TNT (5 sticks) | 10.00 | +—————-+————+
> 1. 找出vend_id = 1002 或者 1003 并且价格大于等于10的数据。
> 2. 注意使用括号调整优先级,and优先级最高,如果不加括号,输出的结果会不同。
* in操作符
mysql> select vend_id,prod_name,prod_price from products where vend_id in (1001,1002,1003) order by prod_name; +———+—————-+————+ | vend_id | prod_name | prod_price | +———+—————-+————+ | 1001 | .5 ton anvil | 5.99 | | 1001 | 1 ton anvil | 9.99 | | 1001 | 2 ton anvil | 14.99 | | 1003 | Bird seed | 10.00 | | 1003 | Carrots | 2.50 | | 1003 | Detonator | 13.00 | | 1002 | Fuses | 3.42 | | 1002 | Oil can | 8.99 | | 1003 | Safe | 50.00 | | 1003 | Sling | 4.49 | | 1003 | TNT (1 stick) | 2.50 | | 1003 | TNT (5 sticks) | 10.00 | +———+—————-+————+
> 1. 找出vend_id为1001,1002,1003的所有值。
* not in操作符
mysql> select vend_id,prod_name from products where vend_id not in (1002,1003); +———+————–+ | vend_id | prod_name | +———+————–+ | 1001 | .5 ton anvil | | 1001 | 1 ton anvil | | 1001 | 2 ton anvil | | 1005 | JetPack 1000 | | 1005 | JetPack 2000 | +———+————–+
> 1. 找出vend_id不在1002和1003的数据。
# 第8章 用通配符进行过滤(like操作符,%和_通配符)
* %通配符
mysql> select prod_id,prod_name from products where prod_name like “%anvil%”; +———+————–+ | prod_id | prod_name | +———+————–+ | ANV01 | .5 ton anvil | | ANV02 | 1 ton anvil | | ANV03 | 2 ton anvil | +———+————–+
> 1. 查询包含"anvil“的数据。
> 2. %就是包含任意个数的字符。
* _通配符
mysql> select prod_id,prod_name from products where prod_name like “_ ton anvil”; +———+————-+ | prod_id | prod_name | +———+————-+ | ANV02 | 1 ton anvil | | ANV03 | 2 ton anvil | +———+————-+
> 1. 找出prod_name的字符串为”x ton anvil"的数据。
> 2. _通配符表示一个字符。
# 第9章 正则表达式进行搜索(regexp)
* 匹配基本字符
mysql> select prod_name from products where prod_name regexp “.000”; +————–+ | prod_name | +————–+ | JetPack 1000 | | JetPack 2000 | +————–+
> 1. 匹配prod_name中包含的有x000的。.表示一个字符.
* 进行or匹配
mysql> select prod_name from products where prod_name regexp ‘1000|2000’; +————–+ | prod_name | +————–+ | JetPack 1000 | | JetPack 2000 | +————–+
> 1. 匹配prod_name中包含的有1000和2000的数据。
> 2. |是正则表达式的or操作符.
* 匹配几个字符之一
mysql> select prod_name from products where prod_name regexp ‘[123] ton’; +————-+ | prod_name | +————-+ | 1 ton anvil | | 2 ton anvil | +————-+
> 1. [123]是匹配1或者2或者3。
> 2. 效果同'[1|2|3] ton'。‘|’可以省略。
需要注意要用[]来定义,否则会出现问题:
mysql> select prod_name from products where prod_name regexp ‘1|2|3 ton’; +—————+ | prod_name | +—————+ | 1 ton anvil | | 2 ton anvil | | JetPack 1000 | | JetPack 2000 | | TNT (1 stick) | +—————+
> 1. 这里没有用[]括起来,要查询的结果也就不正确了。这里查询的结果是包含'1','2'和‘3 tom'的字符串数据。
* 匹配范围
mysql> select prod_name from products where prod_name regexp ‘[0-5] ton’; +————–+ | prod_name | +————–+ | .5 ton anvil | | 1 ton anvil | | 2 ton anvil | +————–+
> 1. [0-5]匹配0至5的任意字符。
> 2. [a-z] : 任意小写字符;[A-Z]:任意大写字符;[0-9]:数字字符。
* 匹配特殊字符
mysql> select vend_name from vendors where vend_name regexp ‘\.’; +————–+ | vend_name | +————–+ | Furball Inc. | +————–+
> 1. '\\\\.'匹配带有.的数据。
> 2. mysql转移字符用双斜杠来表示。
* 匹配多个实例
重复元字符|说明
|:-:|:-:|
*|0个或多个匹配
+|1个或多个匹配(等于{1,})
?|0个或1个匹配(等于{0,1})
{n}|指定数目的匹配
{n,}|不少于指定数目的匹配
{n,m}|匹配数目范围
mysql> select prod_name from products where prod_name regexp ‘\([0-9] sticks?\)’; +—————-+ | prod_name | +—————-+ | TNT (1 stick) | | TNT (5 sticks) | +—————-+
> 1.匹配(数字 stick/sticks)的数据。\\\\(是转移字符,s?表示的是s字符有0个或者1个。
mysql> select prod_name from products where prod_name regexp ‘[0-9]{4}’; +————–+ | prod_name | +————–+ | JetPack 1000 | | JetPack 2000 | +————–+
> 1. [0-9]{4}表示4个任意数字字符。所以这条查询算法就是找出包含4个数字的数据。
* 定位符
^:表示文本的开头;$:表示文本的结尾。
mysql> select prod_name from products where prod_name regexp ‘^[0-9\.]’; +————–+ | prod_name | +————–+ | .5 ton anvil | | 1 ton anvil | | 2 ton anvil | +————–+
> 1. \^[0-9\\.] : 表示找出文本开始为数字或者.的数据。
# 第10章 创建计算字段(拼接字段,使用别名,执行算术计算)
* 拼接字段
mysql> select concat(vend_name,’(‘,vend_country,’)’) from vendors; +—————————————-+ | concat(vend_name,’(‘,vend_country,’)’) | +—————————————-+ | Anvils R Us(USA) | | LT Supplies(USA) | | ACME(USA) | | Furball Inc.(USA) | | Jet Set(England) | | Jouets Et Ours(France) | +—————————————-+
> 1. 利用concat()函数设置输出结果。
> 2. concat():字符串拼接函数,函数中子字符串用的逗号进行分隔。
* 消除前后空格
mysql> select concat(trim(vend_name),’(‘,vend_country,’)’) from vendors; +———————————————-+ | concat(trim(vend_name),’(‘,vend_country,’)’) | +———————————————-+ | Anvils R Us(USA) | | LT Supplies(USA) | | ACME(USA) | | Furball Inc.(USA) | | Jet Set(England) | | Jouets Et Ours(France) | +———————————————-+
> 1. 利用trim()函数消除左右空格。
> 2. rtrim()和ltrim()分别是消除右空格和左空格。
* 使用别名
mysql> select concat(trim(vend_name),’(‘,vend_country,’)’) as vend_title from vendors; +————————+ | vend_title | +————————+ | Anvils R Us(USA) | | LT Supplies(USA) | | ACME(USA) | | Furball Inc.(USA) | | Jet Set(England) | | Jouets Et Ours(France) | +————————+
> 1. 格式为:select 列 as 别名 from 表名;
* 执行算术计算
mysql> select prod_id,quantity,item_price,quantity*item_price as price from orderitems where order_num = 20005; +———+———-+————+——-+ | prod_id | quantity | item_price | price | +———+———-+————+——-+ | ANV01 | 10 | 5.99 | 59.90 | | ANV02 | 3 | 9.99 | 29.97 | | TNT2 | 5 | 10.00 | 50.00 | | FB | 1 | 10.00 | 10.00 | +———+———-+————+——-+
> 1. 第4列为数量和单价相乘的结果。( + - * /)都可以。
> 2. 利用了as作为第4列别名。
# 第11章 使用数据处理函数
## 11.1 文本处理函数
函数|说明|
|:-:|:-:|
left()|返回串最左边的字符
right()|返回串最右边的字符
length()|返回串的长度
lower()|转换成小写
upper()|转换成大写
ltrim()|删除左边空格|
trim()|删除左右边空格
rtrim()|删除右边空格
locate()|找出一个子串
substring()|返回子串的字符
soundex()|返回串的发音值
* upper()函数的使用
mysql> select vend_name,upper(vend_name) as upper_name from vendors; +—————-+—————-+ | vend_name | upper_name | +—————-+—————-+ | Anvils R Us | ANVILS R US | | LT Supplies | LT SUPPLIES | | ACME | ACME | | Furball Inc. | FURBALL INC. | | Jet Set | JET SET | | Jouets Et Ours | JOUETS ET OURS | +—————-+—————-+
> 1. 第二列变成大写
* soundex()函数的使用
mysql> select cust_name,cust_contact from customers where soundex(cust_contact) = soundex(‘y lie’); +————-+————–+ | cust_name | cust_contact | +————-+————–+ | Coyote Inc. | Y Lee | +————-+————–+
> 1. soundex()函数是判断两者的发音是否相同,比如数据库中的为Y Lee与输出的y lie两者发音相同。
## 11.2 数值处理函数
函数|说明|
|:-:|:-:|
abs()|绝对值|
cos()|余弦|
sin()|正弦
tan()|正切
pi()|pi
exp()|指数值
mod()|余数
sqrt()|平方根
## 11.3 日期和时间处理函数
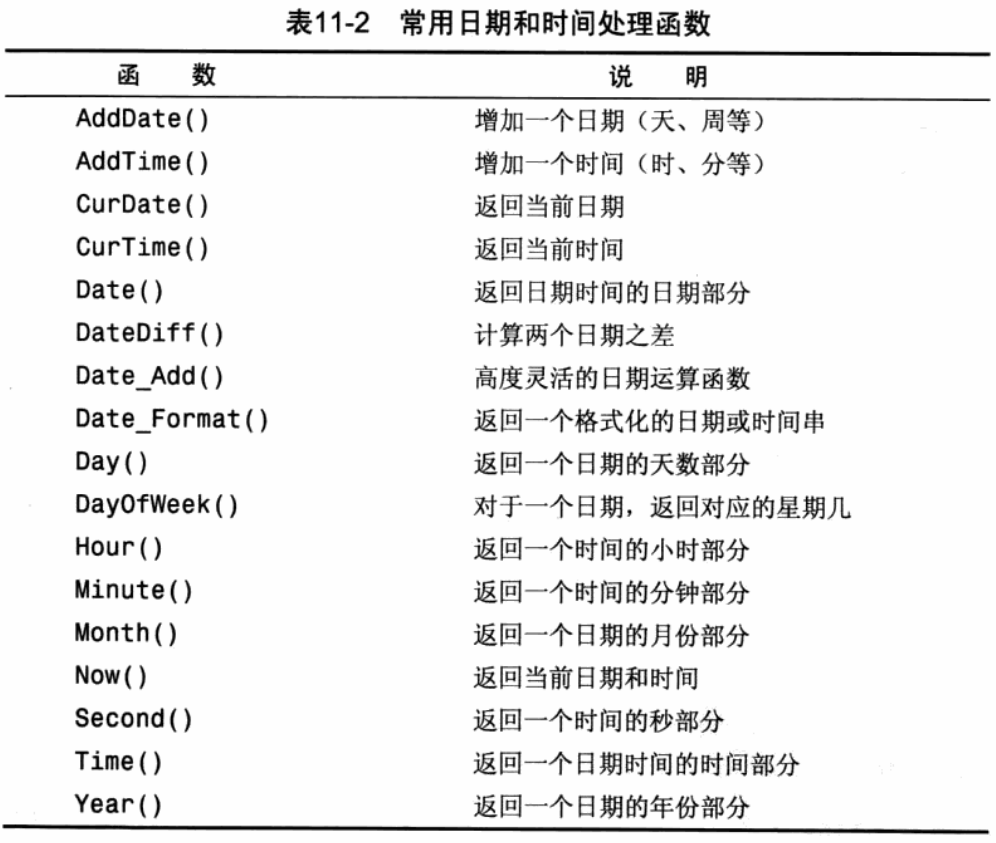
* date()函数的使用
mysql> select cust_id,order_num,order_date from orders where date(order_date)=’2005-09-01’; +———+———–+———————+ | cust_id | order_num | order_date | +———+———–+———————+ | 10001 | 20005 | 2005-09-01 00:00:00 | +———+———–+———————+
> 1. date()函数查询抽取出日期来进行比较。
* 检索出某个月的数据处理方法?
1. 方法1:
mysql> select cust_id,order_num,order_date from orders where date(order_date) between ‘2005-09-01’ and ‘2005-09-30’; +———+———–+———————+ | cust_id | order_num | order_date | +———+———–+———————+ | 10001 | 20005 | 2005-09-01 00:00:00 | | 10003 | 20006 | 2005-09-12 00:00:00 | | 10004 | 20007 | 2005-09-30 00:00:00 | +———+———–+———————+
> 1. 使用between 起始日期 and 终止日期 这种格式来判断。
> 2. 这种方法不方便。
2. 方法2:
mysql> select cust_id,order_num,order_date from orders where year(order_date)=’2005’ and month(order_date)=’09’; +———+———–+———————+ | cust_id | order_num | order_date | +———+———–+———————+ | 10001 | 20005 | 2005-09-01 00:00:00 | | 10003 | 20006 | 2005-09-12 00:00:00 | | 10004 | 20007 | 2005-09-30 00:00:00 | +———+———–+———————+
> 1. 使用year()和month()函数来获取年和月份。
# 第12章 汇总数据
函数|说明
|:-:|:-:|
avg()|平均值
count()|列的数目
max()|当前列的最大值
min()|当前列的最小值
sum()|当前列的之和
* avg()函数
mysql> select avg(prod_price) as price_avg from products where vend_id = 1003; +———–+ | price_avg | +———–+ | 13.212857 | +———–+
> 1. 查询出vend_id = 1003的平均价格;
> 2. avg()函数为求平均的价格;
> 3. 值为null的行将会被忽略。
* count()函数
1. count(*)的使用
mysql> select count(*) as num_cust from customers; +———-+ | num_cust | +———-+ | 5 | +———-+
> 1. 找出customers表中的所有行的数目;
> 2. count(*)将统计任意值的行,包括null值。
2. count(列名称)的使用
mysql> select count(cust_email) as num_cust from customers; +———-+ | num_cust | +———-+ | 3 | +———-+
> 1. cust_email中有null值,所以显示的结果就为3。(总共是5行)
* max()函数
mysql> select max(prod_price) as max_price from products; +———–+ | max_price | +———–+ | 55.00 | +———–+
> 1. 找出最大值
> 2. 忽略null值。
* min()函数
mysql> select min(prod_price) as min_price from products; +———–+ | min_price | +———–+ | 2.50 | +———–+
> 1. 找出最小值,且会忽略null行。
* sum()函数
mysql> select sum(item_price * quantity) as total_price from orderitems where order_num = 20005; +————-+ | total_price | +————-+ | 149.87 | +————-+
> 1. 返回价格之和,且会忽略null的行。
* 用distinct聚合不同值
mysql> select avg(distinct prod_price) as avg_price from products where vend_id = 1003; +———–+ | avg_price | +———–+ | 15.998000 | +———–+
> 1. 使用distinct就是将相同的值只显示1个。
* 组合聚合函数
mysql> select count(*) as num_items,avg(prod_price) as avg_price,min(prod_price) as min_price,max(prod_price) as max_price from products; +———–+———–+———–+———–+ | num_items | avg_price | min_price | max_price | +———–+———–+———–+———–+ | 14 | 16.133571 | 2.50 | 55.00 | +———–+———–+———–+———–+
# 第13章 分组数据(group by/having/order by的使用)
* group by创建分组
mysql> select vend_id,count(*) as num_prods from products group by vend_id; +———+———–+ | vend_id | num_prods | +———+———–+ | 1001 | 3 | | 1002 | 2 | | 1003 | 7 | | 1005 | 2 | +———+———–
> 1. 通过vend_id创建分组;
> 2. 如果当前列中的行有null值,会单独归为一行,多个null值归为一组。
* having分组过滤
mysql> select cust_id,count() as orders from orders group by cust_id having count()>=2; +———+——–+ | cust_id | orders | +———+——–+ | 10001 | 2 | +———+——–+
> 1. 找出订单数大于等于2的顾客。
> 2. where是在数据分组前进行过滤,having是在数据分组之后进行过滤。
* where与having的共同使用
mysql> mysql> select vend_id,count() as num_prod from products where prod_price >= 10 group by vend_id having count() >= 2; +———+—————–+ | vend_id | order_nnum_prod | +———+—————–+ | 1003 | 4 | | 1005 | 2 | +———+—————–+
> 1. where是过滤掉价格小于10的数据,通过group by分组,having过滤掉小于2的数据。
* 分组和order by排序
mysql> select order_num,sum(quantityitem_price) as ordertotal from orderitems group by order_num having sum(quantityitem_price) >= 50 order by ordertotal; +———–+————+ | order_num | ordertotal | +———–+————+ | 20006 | 55.00 | | 20008 | 125.00 | | 20005 | 149.87 | | 20007 | 1000.00 | +———–+————+
> 1. 最后通过group by将分组后的数据进行排序。
# 第14章 使用子查询(Where条件下和计算字段函数下的子查询)
# 14.1 where条件下的
mysql> select cust_name,cust_contact from customers where cust_id in ( select cust_id from orders where order_num in ( select order_num from orderitems where prod_id = ‘TNT2’)); +—————-+————–+ | cust_name | cust_contact | +—————-+————–+ | Coyote Inc. | Y Lee | | Yosemite Place | Y Sam | +—————-+————–+
> 1. 找出产品类型为TNT2的顾客信息。这就要求需要用到子查询。
> 2. 子查询一般和in操作符结合使用。
# 14.2 计算字段函数下的
ysql> select cust_name,cust_state,(select count(*) from orders where orders.cust_id = customers.cust_id) as order_num from customers; +—————-+————+———–+ | cust_name | cust_state | order_num | +—————-+————+———–+ | Coyote Inc. | MI | 2 | | Mouse House | OH | 0 | | Wascals | IN | 1 | | Yosemite Place | AZ | 1 | | E Fudd | IL | 1 | +—————-+————+———–+
> 1. 找出每个客户的订单数。这里用到了count(*)聚合计算函数,和表的级联(orders.cust_id = customers.cust_id)。
> 2. 表的级联一定要指定前面的表名,否则会发成冲突。
# 第15章 联结表
# 15.1 联结多个表
mysql> select prod_name,vend_name,prod_price,quantity from orderitems,products,vendors where products.vend_id = vendors.vend_id and products.prod_id = orderitems.prod_id and order_num = 20005; +—————-+————-+————+———-+ | prod_name | vend_name | prod_price | quantity | +—————-+————-+————+———-+ | .5 ton anvil | Anvils R Us | 5.99 | 10 | | 1 ton anvil | Anvils R Us | 9.99 | 3 | | TNT (5 sticks) | ACME | 10.00 | 5 | | Bird seed | ACME | 10.00 | 1 | +—————-+————-+————+———-+
> 1. 联结表操作,通过where子句中的主键和外键的相等判断即可。
# 15.2 内部链接(<表名1> inner join <表名2> on <表1.外键 = 表2.主键>)
* 二个表的内部联结查询语句
mysql> select vend_name,prod_name,prod_price from vendors inner join products on products.vend_id = vendors.vend_id; +————-+—————-+————+ | vend_name | prod_name | prod_price | +————-+—————-+————+ | Anvils R Us | .5 ton anvil | 5.99 | | Anvils R Us | 1 ton anvil | 9.99 | | Anvils R Us | 2 ton anvil | 14.99 | | LT Supplies | Fuses | 3.42 | | LT Supplies | Oil can | 8.99 | | ACME | Detonator | 13.00 | | ACME | Bird seed | 10.00 | | ACME | Carrots | 2.50 | | ACME | Safe | 50.00 | | ACME | Sling | 4.49 | | ACME | TNT (1 stick) | 2.50 | | ACME | TNT (5 sticks) | 10.00 | | Jet Set | JetPack 1000 | 35.00 | | Jet Set | JetPack 2000 | 55.00 | +————-+—————-+————+
> 1. 内部联结就是等值联结。等同于where 表1.x = 表2.x;
* 三个表内部联结查询语句
mysql> select prod_name,vend_name,prod_price,quantity from (products inner join vendors on products.vend_id = vendors.vend_id) inner join orderitems on products.prod_id = orderitems.prod_id where order_num = 20005; +—————-+————-+————+———-+ | prod_name | vend_name | prod_price | quantity | +—————-+————-+————+———-+ | .5 ton anvil | Anvils R Us | 5.99 | 10 | | 1 ton anvil | Anvils R Us | 9.99 | 3 | | TNT (5 sticks) | ACME | 10.00 | 5 | | Bird seed | ACME | 10.00 | 1 | +—————-+————-+————+———-+
> 1. 多个表的联结需要注意下格式.
# 第16章 高级联结(自联结、自然联结、外部联结)
## 16.1 自联结
自己联结自己(联结的表相同)。
mysql> select p1.prod_id,p1.prod_name from products as p1 ,products as p2 where p1.vend_id = p2.vend_id and p2.prod_id = ‘DTNTR’; +———+—————-+ | prod_id | prod_name | +———+—————-+ | DTNTR | Detonator | | FB | Bird seed | | FC | Carrots | | SAFE | Safe | | SLING | Sling | | TNT1 | TNT (1 stick) | | TNT2 | TNT (5 sticks) | +———+—————-+
## 16.2 自然连接
## 16.3 外部联结
* 内部联结(inner join)
mysql> select customers.cust_id,orders.order_num from customers inner join orders on customers.cust_id = orders.cust_id; +———+———–+ | cust_id | order_num | +———+———–+ | 10001 | 20005 | | 10001 | 20009 | | 10003 | 20006 | | 10004 | 20007 | | 10005 | 20008 | +———+———–+
* 左外部联结(left outer join)
mysql> select customers.cust_id,orders.order_num from customers left outer join orders on customers.cust_id = orders.cust_id; +———+———–+ | cust_id | order_num | +———+———–+ | 10001 | 20005 | | 10001 | 20009 | | 10002 | NULL | | 10003 | 20006 | | 10004 | 20007 | | 10005 | 20008 | +———+———–+
> 1. left outer join是以左边的表为主。
* 右外部联结(right outer join)
mysql> select customers.cust_id,orders.order_num from customers right outer join orders on customers.cust_id = orders.cust_id; +———+———–+ | cust_id | order_num | +———+———–+ | 10001 | 20005 | | 10001 | 20009 | | 10003 | 20006 | | 10004 | 20007 | | 10005 | 20008 | +———+———–+
> 1. right outer join以右边的表显示为主.
> 2. 做外部表和右外部表可以相互转换。
# 第17章 组合查询(union)
## 17.1 使用union
mysql> select vend_id,prod_id,prod_price from products where prod_price <= 5 union select vend_id,prod_id,prod_price from products where vend_id in (1001,1002); +———+———+————+ | vend_id | prod_id | prod_price | +———+———+————+ | 1003 | FC | 2.50 | | 1002 | FU1 | 3.42 | | 1003 | SLING | 4.49 | | 1003 | TNT1 | 2.50 | | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1002 | OL1 | 8.99 | +———+———+————+
> 1. 使用union将两个表的查询结果组合在一起。
> 2. union中的每个查询必须包含相同的列、表达式或者聚集函数。
## 17.2 消除或者包含重复的行(union all/union)
mysql> select vend_id,prod_id,prod_price from products where prod_price <= 5 union all select vend_id,prod_id,prod_price from products where vend_id in (1001,1002); +———+———+————+ | vend_id | prod_id | prod_price | +———+———+————+ | 1003 | FC | 2.50 | | 1002 | FU1 | 3.42 | | 1003 | SLING | 4.49 | | 1003 | TNT1 | 2.50 | | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1002 | FU1 | 3.42 | | 1002 | OL1 | 8.99 | +———+———+————+
> 1. 使用union all 可以显示全部的查询结果,使用union就会默认删除掉重复的结果。
## 17.2 对组合查询结果排序(order by)
mysql> select vend_id,prod_id,prod_price from products where prod_price <= 5 union all select vend_id,prod_id,prod_price from products where vend_id in (1001,1002) order by vend_id,prod_price; +———+———+————+ | vend_id | prod_id | prod_price | +———+———+————+ | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1002 | FU1 | 3.42 | | 1002 | FU1 | 3.42 | | 1002 | OL1 | 8.99 | | 1003 | FC | 2.50 | | 1003 | TNT1 | 2.50 | | 1003 | SLING | 4.49 | +———+———+————+
> 1. order by 在组合查询中只能写在最后面,但是能够对所有的结果进行统一的排序。
# 第18章 全文本搜索(metch() against())
## 18.1 使用全文本搜索
mysql> select note_text from productnotes where match(note_text) against(‘rabbit’); +———————————————————————————————————————-+ | note_text | +———————————————————————————————————————-+ | Customer complaint: rabbit has been able to detect trap, food apparently less effective now. | | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | +———————————————————————————————————————-+
> 1. metach():指定搜索的列,against():指定要搜索的表达式。
> 2. 全文搜索只有指定MyISAM搜索引擎才可以。
> 3. 用fulltext指示全文搜索索引,参考productnotes表的创建。
## 18.2 全文搜索具有排序作用
mysql> select note_text,match(note_text) against(‘rabbit’) as rank from productnotes; +———————————————————————————————————————————————————–+——————–+ | note_text | rank | +———————————————————————————————————————————————————–+——————–+ | Customer complaint: Sticks not individually wrapped, too easy to mistakenly detonate all at once. Recommend individual wrapping. | 0 | | Can shipped full, refills not available. Need to order new can if refill needed. | 0 | | Safe is combination locked, combination not provided with safe. This is rarely a problem as safes are typically blown up or dropped by customers. | 0 | | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | 1.5905543565750122 | | Included fuses are short and have been known to detonate too quickly for some customers. Longer fuses are available (item FU1) and should be recommended. | 0 | | Matches not included, recommend purchase of matches or detonator (item DTNTR). | 0 | | Please note that no returns will be accepted if safe opened using explosives. | 0 | | Multiple customer returns, anvils failing to drop fast enough or falling backwards on purchaser. Recommend that customer considers using heavier anvils. | 0 | | Item is extremely heavy. Designed for dropping, not recommended for use with slings, ropes, pulleys, or tightropes. | 0 | | Customer complaint: rabbit has been able to detect trap, food apparently less effective now. | 1.6408053636550903 | | Shipped unassembled, requires common tools (including oversized hammer). | 0 | | Customer complaint: Circular hole in safe floor can apparently be easily cut with handsaw. | 0 | | Customer complaint: Not heavy enough to generate flying stars around head of victim. If being purchased for dropping, recommend ANV02 or ANV03 instead. | 0 | | Call from individual trapped in safe plummeting to the ground, suggests an escape hatch be added. Comment forwarded to vendor. | 0 | +———————————————————————————————————————————————————–+——————–
> 1. 全文搜索的结果默认会有排序的,权重较高的排在前面,没有查询的显示为0,本结果中就有两条为1.x的结果。
## 18.3 扩展查询结果
mysql> select note_text from productnotes where match(note_text) against(‘anvils’ with query expansion); +———————————————————————————————————————————————————-+ | note_text | +———————————————————————————————————————————————————-+ | Multiple customer returns, anvils failing to drop fast enough or falling backwards on purchaser. Recommend that customer considers using heavier anvils. | | Customer complaint: Sticks not individually wrapped, too easy to mistakenly detonate all at once. Recommend individual wrapping. | | Customer complaint: Not heavy enough to generate flying stars around head of victim. If being purchased for dropping, recommend ANV02 or ANV03 instead. | | Please note that no returns will be accepted if safe opened using explosives. | | Customer complaint: rabbit has been able to detect trap, food apparently less effective now. | | Customer complaint: Circular hole in safe floor can apparently be easily cut with handsaw. | | Matches not included, recommend purchase of matches or detonator (item DTNTR). | +———————————————————————————————————————————————————-+
> 1. 除了显示包含against指定的内容之外,还会扩展查询的结果。
> 2. 在against("anvils" with query expansion)。
## 18.4 布尔文本搜索
布尔操作符|说明
|:-:|:-:|
+|包含,词必须在
-|排除,词不能出现
>|包含,而且增加等级值
<|包含,减少等级值
()|组成子表达式
*|通配符
“”| 组成一个短语
*
mysql> select note_text from productnotes where match(note_text) against(‘heavy -rope*’ in boolean mode); +———————————————————————————————————————————————————+ | note_text | +———————————————————————————————————————————————————+ | Customer complaint: Not heavy enough to generate flying stars around head of victim. If being purchased for dropping, recommend ANV02 or ANV03 instead. | +———————————————————————————————————————————————————+
> 1. '-' 为除去这个rope*的单词的结果
*
mysql> select note_text from productnotes where match(note_text) against(‘+rabbit +bait’ in boolean mode); +———————————————————————————————————————-+ | note_text | +———————————————————————————————————————-+ | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | +———————————————————————————————————————-+
> 1. 搜索结果必须包含rabbit和bait词。
*
mysql> select note_text from productnotes where match(note_text) against(‘rabbit bait’ in boolean mode); +———————————————————————————————————————-+ | note_text | +———————————————————————————————————————-+ | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | | Customer complaint: rabbit has been able to detect trap, food apparently less effective now. | +———————————————————————————————————————-+
> 1. 搜索的结果包含rabiit或者bait中的至少1个。
*
mysql> select note_text from productnotes where match(note_text) against(‘“rabbit bait”’ in boolean mode); +———————————————————————————————————————-+ | note_text | +———————————————————————————————————————-+ | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | +———————————————————————————————————————-+
> 1. 包含“rabiit bait"这个整个词组进行搜索。
*
mysql> select note_text from productnotes where match(note_text) against(‘>rabbit <carrot’ in boolean mode); +———————————————————————————————————————-+ | note_text | +———————————————————————————————————————-+ | Quantity varies, sold by the sack load. All guaranteed to be bright and orange, and suitable for use as rabbit bait. | | Customer complaint: rabbit has been able to detect trap, food apparently less effective now. | +———————————————————————————————————————-+
> 1. 匹配rabiit和carrot,前者增加等级,后者降级。
*
mysql> select note_text from productnotes where match(note_text) against(‘+safe +(<combination)’ in boolean mode); +—————————————————————————————————————————————————+ | note_text | +—————————————————————————————————————————————————+ | Safe is combination locked, combination not provided with safe. This is rarely a problem as safes are typically blown up or dropped by customers. | +—————————————————————————————————————————————————+
> 1. 匹配safe和combination,降低后者等级。
# 第20章 更新和删除数据(update和delete)
## 20.1 update的使用
mysql> update customers set cust_name = ‘The fudds’,cust_email= ‘elmer@fudds.com’ where cust_id = 10005; Query OK, 1 row affected (0.11 sec) Rows matched: 1 Changed: 1 Warnings: 0
> 1. update <表名> set 列名称1=值,列名称2=值... where <条件>。
> 2. 要设置多个列数的值,中间用逗号进行分隔。
## 20.2 delete的使用
mysql> delete from customers where cust_id=10006; Query OK, 0 rows affected (0.00 sec)
> 1. 格式:delete from <表名称> where <条件>。
# 第22章 视图
视图是虚拟的表。视图包含的不是数据而是根据需要检索数据的查询。视图提供了一种select语句层次的封装,可以用来简化数据处理以及重新格式化基础数据或者保护基础数据。
## 22.1 使用视图简化复杂的联结
mysql> create view productcustomers as select cust_name,cust_contact,prod_id from customers,orders,orderitems where customers.cust_id = orders.cust_id and orderitems.order_num = orders.order_num; Query OK, 0 rows affected (0.44 sec)
mysql> select * from productcustomers; +—————-+————–+———+ | cust_name | cust_contact | prod_id | +—————-+————–+———+ | Coyote Inc. | Y Lee | ANV01 | | Coyote Inc. | Y Lee | ANV02 | | Coyote Inc. | Y Lee | TNT2 | | Coyote Inc. | Y Lee | FB | | Coyote Inc. | Y Lee | FB | | Coyote Inc. | Y Lee | OL1 | | Coyote Inc. | Y Lee | SLING | | Coyote Inc. | Y Lee | ANV03 | | Wascals | Jim Jones | JP2000 | | Yosemite Place | Y Sam | TNT2 | | The fudds | E Fudd | FC | +—————-+————–+———+
> 1. 通过create view <视图名> as select语句来创建视图,然后通过视图名称来获取查询的数据。
## 22.2 使用视图重新格式化检索出来的数据
mysql> create view vendorlocations as select concat(rtrim(vend_name),’(‘,rtrim(vend_country),’)’) as vent_title from vendors order by vend_name; Query OK, 0 rows affected (0.01 sec)
mysql> select * from vendorlocations; +————————+ | vent_title | +————————+ | ACME(USA) | | Anvils R Us(USA) | | Furball Inc.(USA) | | Jet Set(England) | | Jouets Et Ours(France) | | LT Supplies(USA) | +————————+
> 1. 可以将有concat的select语句创建视图。
## 22.3 使用视图过滤不要的数据
mysql> create view customeremail as select cust_id,cust_name,cust_email from customers where cust_email is not null; Query OK, 0 rows affected (0.00 sec)
mysql> select * from customeremail; +———+—————-+———————+ | cust_id | cust_name | cust_email | +———+—————-+———————+ | 10001 | Coyote Inc. | ylee@coyote.com | | 10003 | Wascals | rabbit@wascally.com | | 10004 | Yosemite Place | sam@yosemite.com | | 10005 | The fudds | elmer@fudds.com | +———+—————-+———————+ ```
- 过滤掉了email数据为空的数据。
2019-2-25